【PConline杂谈】随着RTX 3080显卡性能的提升,可以透露更多关于NVIDIA Ampere架构和RTX 30系列显卡的信息。今天,我们将根据我们的实测和官方信息,与您一起分析新架构显卡性能飙升的秘诀。
全新的SM单元设计、升级后的Tensor Core、RT Core、8nm工艺以及NVIDIA Ampere架构上的GDDR6X内存,为RTX 30系列显卡带来了惊人的性能提升,而面向未来的PCIe 4.0、HDMI 2.1、RTX IO、Reflex等新特性,为NVIDIA下一阶段的发展奠定了良好的基础。
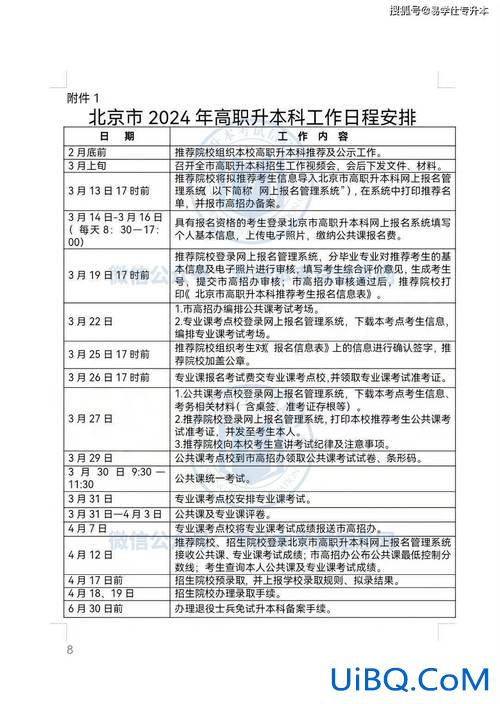
SM单元再优化,CUDA核心翻倍带动性能暴涨
RTX 3090的性能是TITAN RTX的1.5倍,RTX 3080的性能是RTX 2080的2倍,RTX 3070的性能略高于RTX 2080 Ti和RTX 2070的1.6倍。
CUDA核心数的计算方法一直是一个SM模块下的FP32算术单元数。按照原来的定义方法,一套完整的INT(整数运算单元)FP(浮点运算单元)组合需要被视为一个处理器单元,但是在目前的应用场景下,绝大多数运算(比如游戏计算)主要考察的是FP32单元的性能.
Turing架构(左)和Ampere架构(右)SM单元示意图
所以老黄从费米架构开始,从直接用FP32单元=CUDA核心这样的计算方式,.就开始使用了,以图灵为例,每个SM单元包含64个CUDA核,看上图中带有FP32的网格就可以统计出64个FP32(4x16)单元。在这一代NVIDIA Ampere架构之后,虽然整体非布局结构类似于图灵,但中间一组数据路径仍然是全FP32单元设计,但左边的独立INT32单元数据路径则变成“FP32+INT32”单元.
每组独立的FP32单元包含16组FP32 CUDA内核,每个时钟周期可执行16条FP32指令,而另一条数据路径包含16个FP32和16个INT32内核,每个时钟周期仍可执行多达16条FP32指令。在这种设计下,每个SM单元中的分区可以选择每个时钟周期执行32条FP32指令或16条FP32和16条INT32指令。
这意味着在全新的安培架构中,一个SM单元每个时钟周期最多可以执行128条FP32指令,是图灵架构的两倍。同时每时钟周期可执行64条FP32指令和64条INT32指令,兼顾了性能和通用性。
RTX 3080核心示意图,拥有68组SM单元
按照FP32台=CUDA核心数的计算方法,配备RTX 3080的68组SM机组中有68*128 FP32台=8704 FP32台,与官方标称CUDA核心数一致。
但这种方式带来的CUDA核心的“翻倍”并不直接意味着Ampere架构可以凭借“堆核”将性能翻倍,因为在这种设计下,在执行纯FP32计算时只能直接将性能翻倍(比如“挖矿”的性能几乎翻倍)。
在人们比较关注的游戏性能等实际应用中,虽然FP32单元会被调动更多(浮点运算),但也需要调用INT32(整数预算)等其他单元的各种运算,所以在游戏中几乎不可能实现性能的双提升。
在NVIDIA官网对Ampere架构的简要介绍中,新的SM单元带来了“2x FP32吞吐量”,而不是直接标注两倍的FP32单元数量,考虑到字面意思会被曲解。毕竟,在这种架构下,只要执行纯浮点运算,性能就有可能翻倍。
虽然这种结构无法直接将性能翻倍,但整体计算效率的提升是实实在在的,这也是NVIDIA Ampere GPU在实际应用场景中能够达到远图灵架构性能的核心原因之一。
Tensor Core与RT Core齐升级,4K+光追无压力
光线追踪和度学习超级采样(DLSS)作为RTX 20系列显卡的两大主要新技术,共同将游戏的画质和性能提升到了一个新的维度。
RT Core主要影响实时光学跟踪性能。基于图灵架构的第一代RT Core可提供高达34T的RT性能,而DLSS技术的处理能力主要由Tensor Core决定。图灵可提供高达89T的Tensor性能,而传统SM单元提供11T的FP32计算能力。
Turing架构渲染时间(RTX 2080
Super)专门的光追单元可以大幅提升实时光线渲染能力,在Turing架构的RTX 2080 Super中,渲染同一演示图像时使用传统着色器需要51ms,使用RT Core渲染一帧图像所需的时间仅为19ms,渲染速度提升了2.68倍,而在打开DLSS后,更是渲染速度缩短至13ms,性能表现进一步提高,这两项技术也为游戏厂商们推出画面表现更出色的游戏打下基础。
不过在带来比传统的远超光栅化渲染的光线效果的同时,也对显卡的性能提出了严峻的考验,即便有DLSS技术的加持,这一代的光追游戏始终差点意思,特别在2K甚至4K等高分辨率下,要么为了流畅关闭光追效果,要么为了光追效果忍受帧数下降。
而来到NVIDIA Ampere架构中,这三种单元的性能都获得了显著提升,SM单元的FP32计算性能提升至30T,提升幅度达到2.7倍;然后是RT Core的RT性能提升至58T,提升幅度是1.7倍;最后是Tensor Core的Tensor性能提升至238T,提升幅度更是高达2.67倍。
NVIDIA Ampere渲染时间(RTX 3080)
硬件上的升级带来的也是渲染性能的全面提高,在同样使用RT Core+Tensor Core进行渲染的情况下,RTX 2080 Super需要13ms,而RTX 3080可以将时间缩小至7.5ms,而通过全新的并行处理技术优化,SM、RT Core与Tensor Core三大单元可以同时工作,渲染时间更是可以缩短至6.7ms,对比RTX 2080 Super提升高达94%。
而通过游戏实测可知,RTX 3080已经能在绝大部分游戏中,满足4K分辨率+光线追踪效果拉满的条件下,维持60FPS以上帧数的条件,这也意味着,RTX 30系列已经实现从“能玩”到“可以玩”4K光追游戏的跨越。
全新8nm工艺加成,芯片整体效能激增
跟竞争对手AMD近年来在制程工艺的大动作不同(从格罗方德的12nm直接提升至台积电7nm),NVIDIA近年来的工艺提升可谓非常“低调”,从Pascal(10系列显卡)的台积电16nm工艺到Turing(20系列显卡)的12nm FFN工艺(实际上算是16nm的改良版),制程上的提升并没有它们的性能提升来的激进。
虽然NVIDIA要在Ampere架构上升级制程工艺基本是早已被确认,5月份发布GA100核心也使用上了全新的台积电 7nm工艺,在RTX 30系列显卡正式发布前,大家都以为他们将继续采用这一工艺,而NVIDIA却在发布会上官宣了RTX 30显卡将使用三星的8nm工艺。
这一工艺虽然是在三星10nm工艺的基础上改良而来,但是却为Ampere架构的效能提升立下了汗马功劳,同时也不得不佩服NVIDIA的芯片设计能力。
图片来源igor's LAB
采用12nm FFN工艺的RTX 2080Ti(TU102核心)在764mm²的芯片面积内装入了186亿个晶体管,而这一代的RTX 3080(GA102核心)却能在628mm²的芯片面积内塞入了280亿个晶体管,密度提升几乎翻倍,但稍逊于采用台积电7nm工艺的GA100核心(在828mm²的芯片面积下塞入了540亿个晶体管).
具体密度上,7nm GA100的6521万个/mm²>8nm GA102的4458万个/mm²>12nm的TU 102的2434万个/mm²,三种工艺带来的密度差异还是比较明显的,虽然RTX 30系列没有用上7nm工艺,但是三星8nm工艺对比台积电12nm FFN工艺带来的提升还是非常显著的。
NVIDIA最终选择三星8nm工艺可能也有运行频率上的考量,RTX 3080在拥有比RTX 2080Ti翻倍的CUDA核心数的情况下,仍能获得更高的Boost核心频率,而目前的7nm工艺可能还没法做到这一点,用在超算卡的GA 100则不需要太高的运行频率,此外,不选择台积电7nm工艺可能也有产能方面的考量。
制程工艺的升级还带来了能效比方便的提升,NVIDIA官方宣称在同样的60FPS帧率时,Ampere架构显卡的能耗比可以达到Turing架构显卡的1.9倍,要实现同样的性能表现,前者只需120W多点的功耗,而后者则要240W的功耗,并且前者的还温度低了3°C,噪音也减少了2dB,这个提升还是非常可观的。
GDDR6X显存加持,为极致性能保驾护航
RTX 3090和RTX 3080用上了全新的全新的GDDR6X显存,这也是RTX 30显卡的性能表现得到大幅提升的重要因素之一,特别是在高分辨率、高光追特效等应用场景下,显存的容量和带宽都很容易成为显卡性能的瓶颈。
尤其是在发布会演示的8K@60Hz+全光追特效这种极限应用场景下,性能更加强悍的GDDR6X显存可以让Ampere架构处理器更好地释放性能。
GDDR6X除了在GDDR6对运行频率进行超频,最重要的改进就是首次在显存上使用了PAM4编码。
相比传统的“NRZ”编码方式,PAM4编码可以让显卡在每个时钟周期内传输更多数据(从原来的每个时钟周期发送两位二进制数据,升级为每个时钟周期发送四位二进制数据),这也让GDDR6X的最大显存频率从GDDR6的16Gb/s提升到21Gb/s,也拥有超过1TB/s(1050MB/s)的理论显存带宽上限,这个表现已经达到HBM2的1TB/s带宽的水平。
而在RTX 30系列的实际应用上,目前最强的RTX 3090拥有19.5Gb/s的显存频率,显存带宽也达到936Gb/s,对比RTX 2080 Ti上的GDDR6带宽(616Gb/s)更是提高了52%。
GDDR6X显存除了能在性能上比肩HBM2的水平,也可以在同样的频率下实现更高的显存带宽,进而降低GDDR6X的成本和能耗,未来应该还会下放到更多消费级显卡上。
PCIe 4.0+RTX IO 面向未来的新特性
除了上面提到的一些直接给RTX 30系列显卡带来性能提升的特性,NVIDIA Ampere架构还拥有许多面向未来的新特新,这些新特新目前可能没法给消费者提供直观的使用体验,却代表着显卡市场未来的潜在发展方向。
首先就是在AMD平台上已经应用多时的PCIe4.0,虽然在去年的RX 5000系列已经率先应用在显卡领域,不过该系列的性能表现完全用不上PCIe4.0x16的带宽,AMD这边也没有推出特定的功能来利用这一优势。
而NVIDIA Ampere架构列在优艾设计网_设计客加入对PCIe4.0的支持后,虽然目前的RTX 30系列显卡在理论性能上仍不能跑满通道带宽,在实测环节中跟PCIe3.0对比也没有性能上的差距,但是NVIDIA却专门准备了RTX IO技术来最大化利用PCIe4.0的超大带宽。
在传统的运行方式中,显卡要渲染图像,需要经过如图上复杂的路径:GPU需要通过PCIe通道与CPU进行通讯,并且通过CPU将内存中的文件传输到显存上,再进行读取和渲染,而内存中的游戏文件,也要经过CPU从PCIe通道另一端的硬盘进行读取,数据要经历硬盘—>PCIe—>CPU—>内存—>CPU—>PCIe-—>GPU-—>显存的复杂流程。
这个过程频繁调用CPU与内存,整体效率也不够高,而且由于硬件的木桶效应,整个流程中的硬件都有机会造成性能瓶颈,而且不能最大化利用PCIe通道的带宽。
而NVIDA的RTX IO技术,可以让GPU直接从走PCIe通道的硬盘中直接调用数据,既节省了CPU和内存的占用,也大幅提高了传输效率,可以更好地发挥GPU和显存的性能,搭配PCIe4.0通道的超高带宽,可以最大化高速PCIe4.0硬盘和GPU的性能表现。
从NVIDIA官方提供的展示DEMO来看,RTX IO技术带来的传输效率提升非常明显,对比传统模式下使用PCIe 4.0 SSD和24核线程撕裂者的配置,RTX IO的加载时间只需1.5秒,而前者最快也要5秒,这个表现让它具备相当出色的应用前景。
不过该技术目前还处于初始阶段,未来也得像DLSS、光追技术一样需要游戏独立研发支持,NVIDA这边也得花费不少成本才能完成研发和大规模推广
HDMI 2.1:为8K游戏铺路
采用NVIDIA Ampere架构的RTX 30系列显卡还配备了最新的HDMI2.1显示出书接口,这一接口专门为8K以上的画面传输而设计,传输带宽从HDMI2.0的18Gbps提升到48Gbps,提升幅度达到2.67倍,最大可传输10K@120FPS的视频讯号,而且能完美支持HDR、增强音频回程通道eARC、可变刷新率VRR、快速帧传输QFT、自动低延迟模式ALLM等特性。
不过目前要享受8K游戏的魅力,除了得拥有该接口外,还需要用上RTX 3090以上级别显卡、HDMI 2.1的专用线缆和支持HDMI 2.1接口的8K显示器,短期内该接口依然会是为土豪准备的玩意。
NVIDIA Reflex:决胜分毫,提升电竞表现
NVIDIA Reflex是一个为降低游戏显示延迟的技术,该技术融合GPU和游戏优化,通过硬件和软件的结合动态降低系统延迟,优化的核心精简整个画面输出流程。
在传统的输出流程中,鼠标、键盘和手柄等输入设备发送信号后,经由CPU处理后,需要输入到渲染队列后并由GPU执行渲染,最后再由GOU输出到显示器中,这个过程中,外设输入、PC内部处理和显示器输出都会有一定的延迟,NVIDIA Reflex主要是对PC内部处理的部分进行精简。
该技术直接去掉了交由渲染队列等待的过程,直接向CPU处理过后的数据交由GPU即时进行处理,除了提升传输效率外还释放了CPU的负载,降低延迟的同时也减少了对CPU资源的消耗。
在各项热门游戏中,开启NVIDIA Reflex功能可以有效降低系统延迟,这个提升幅度对游戏玩家,尤其是追求极致响应速度的电竞选手来说非常重要,可以有效提升他们在电竞比赛中的响应表现。
影驰RTX 30系列显卡:散热全面升级 带来极致游戏体验
NVIDIA Ampere架构各项新特性为RTX 30系列显卡带来了非常惊艳的性能表现,影驰作为NVIDIA的核心AIC合作伙伴,也推出了全面覆盖RTX 3090/3080/3070的GAMER、星曜、金属大师、将系列产品。
在完整享受NVIDIA Ampere架构所有新特性的同时,影驰RTX30系列散热器的设计全面升级,更加契合每个系列特性的设计语言,塑造完全不同以往的全新体验,搭配更加优秀的整卡调教及优化,性能强悍稳定无忧,为玩家打造真正的史上最强超级装备,准备入手RTX 30系列显卡的朋友可不要错过了。







 加载中,请稍侯......
加载中,请稍侯......
精彩评论